遺伝的アルゴリズムを使ったポートフォリオの多目的最適化
先日、新NISA関連の調べものをしていた時、以下のような記事を見つけました。
リスク-リターン平面上に、数々の資産の組み合わせ=ポートフォリオの運用結果をプロットし、あるリスクに対して最大のリターンが得られるポートフォリオの集合=効率的フロンティアという概念があるそうです。
これは、多目的最適化でいうパレートフロントと同じ考え方です。多目的最適化では、複数のトレードオフの関係にある目的関数に対して、これ以上どちらの目的も同時に良くすることはできない解の集合=パレートフロントを見つけることが目標です。
パレートフロントを厳密に求めるには時間がかかるため、遺伝的アルゴリズムなどを用いて近似的なパレートフロントを探索する方法が取られています。効率的フロンティア上のポートフォリオについても同様の方法を適用し、リスクとリターンを計算する目的関数を用意し探索すれば、良好なポートフォリオ候補を自動で作成できそうだと思ったので、トライしてみました。
ポートフォリオの成績は以下の条件で計算することにします。
- 資産の種類は現金、日本株、米国株、先進国株、新興国株、米国債券、先進国債券、日本REIT、米国REIT、先進国REIT、コモディティ、金の12個
- ドル建資産は日毎為替レートで円換算して計算
- ポートフォリオは毎月指定比率となるようにリバランス
- 配当金・分配金は毎月再投資
- 売買にかかる手数料や、為替手数料、税金等のコストは考慮しない
計算にはPythonを用います。Pythonの多目的最適化ライブラリpymooを練習として使ってみます。 実は、pymooにはケーススタディとしてポートフォリオ最適化の事例があるのですが、リバランスなどは考慮されていないようでしたので、参考程度にとどめ、新規にスクリプトを作成します。
作成したPythonスクリプトはGitHubに公開しています。
本記事の目次です。
1. データ取得
データはYahoo!ファイナンスから取得します。 各資産クラスのデータは、ETF(上場投資信託)から以下の銘柄を選定して利用することにしました。
| 資産 | 対象ETF | ティッカー | 対象指数 | 設定 |
|---|---|---|---|---|
| 現金 | - | - | - | - |
| 日本株 | NEXT FUNDS TOPIX連動型上場投資信託 | 1306.T | TOPIX | 2008 |
| 米国株 | SPDR S&P 500 ETF Trust | SPY | S&P500指数 | 1993 |
| 先進国株 | バンガード・FTSE先進国市場(除く米国)ETF | VEA | FTSE先進国オールキャップ(除く米国)インデックス | 2007 |
| 新興国株 | バンガード・FTSE・エマージング・マーケッツETF | VWO | FTSEエマージング・マーケッツ・オールキャップ(含む中国A株) | 2005 |
| 米国債券 | バンガードトータル債券市場ETF | BND | ブルームバーグ・バークレイズ米国総合浮動調整インデックス | 2007 |
| 先進国債券 | SPDR ブルームバーグ・バークレイズ世界国債(除く米国)ETF | BWX | ブルームバーグ・バークレイズ・グローバル国債(除く米国)キャップド指数 | 2007 |
| 日本REIT | NEXT FUNDS 東証REIT指数連動型上場投信 | 1343.T | 東証REIT指数 | 2008 |
| 米国REIT | バンガードREIT ETF | VNQ | MSCI US Investable Market Real Estate 25/50 Index | 2004 |
| 先進国REIT | iシェアーズ 先進国(除く米国) REIT ETF | IFGL | FTSE EPRA/NAREIT 先進国不動産 除く米国 | 2007 |
| コモディティ | iシェアーズ S&P GSCI コモディティ・インデックス・トラスト | GSG | S&P GSCI 商品指数 | 2006 |
| 金 | SPDR ゴールド・シェア | GLD | ロンドン金価格 | 2004 |
選定基準としては各資産に該当するETFの中でなるべく長い期間のデータがあることです。日本国債券や新興国REITといった資産も調べたのですが、適当なETFが見当たらなかったので、今回の対象からは除外しました。*1
Yahoo!ファイナンスからはYahoo!ファイナンスAPIを使ってその銘柄に関するデータをダウンロードすることができます。今回選択したETFには分配金が出るものがありますので、株価と分配金のデータをダウンロードすることにします。以下のような形でURLを作成しアクセスすると、株価の時系列データと分配金実績をJSON形式で取得できます。
import requests from io import StringIO import json # urlを作成しjsonを取得 ticker = "SPY" # ここでティッカーシンボルを指定 period = "11y" # 10年データが欲しいので長めにとって切り出す interval = "1d" prefix = "https://query1.finance.yahoo.com/v8/finance/chart/" url = prefix + ticker + "?range=" +period + "&interval=" + interval + "&events=div&includeAdjustedClose=true" response = requests.get(url) str = StringIO(response.text) j = json.load(str)
株価のデータはindicatorsのquote、分配金のデータはeventsのdividendsというフィールドに配置されていますので、それぞれのデータをpandas.DataFrameに変換します。
import pandas as pd # 株価の取得 quote = pd.DataFrame() timestamp = j['chart']['result'][0]['timestamp'] quote.index = pd.to_datetime(timestamp, unit="s") quote.index.name = "timestamp" quote['close'] = j['chart']['result'][0]['indicators']['quote'][0]['close'] # 分配金情報の取得 div_json = j["chart"]["result"][0]["events"]["dividends"] div = pd.DataFrame(list(div_json.values()), columns=['amount', 'date']) div.index = pd.to_datetime(div["date"], unit="s") div.index.name = "timestamp" div = div.drop("date", axis=1) div.columns = ["dividend"]
取得したデータは15~20年ほどのデータ期間がありますが、今回は10年間(2013年末から2023年末)のポートフォリオの成績を見て最適化をすることにします。
それから、ドル建て資産は日本円に換算します。ドル円の為替情報は株価と同様にティッカーをUSDJPY=XとすればYahoo!ファイナンスから取得できます。為替データと株価データをpandas.merge_asofで結合→乗算して、円換算します。
# ここで株価データ取得 price = quote.copy() # ここで為替データ取得 usdjpy = quote.copy() usdjpy = usdjpy.dropna() # 14時間足して日本時間に合わせる price.index = price.index + timedelta(hours=14) # 価格を円換算する merged = pd.merge_asof(price, usdjpy, on="timestamp", direction="nearest") # 最も近いtimestampで結合 merged[price.columns[0]] = merged[merged.columns[1]] * merged[merged.columns[2]] # 円換算 merged = merged.set_index("timestamp") # timestampをindexにする price = pd.DataFrame(merged[price.columns[0]]) # 円換算したものを新たに株価データとする
2. ポートフォリオの成績の計算
次に、毎月リバランスをしながら運用したときの成績を計算します。 ロジックとしては以下です。
- ポートフォリオの各資産クラスの割合を与える
- 初月に定められた割合で資産を購入する
- 毎月の月末に分配金を再投資し、保有株数×価格で各資産の割合を計算。割合が多い場合は売却、割合が少ない場合は購入する。保有株数とトータル評価額を記録しておく
- 最終日まで行ったら、トータル評価額の推移から年率平均リターン(複利計算)とリスクを求める
# 初期設定 amount = quotes.copy() # 資産毎の保有額 amount[:] = 0 num_of_stocks = amount.copy() # 資産毎の持株数 portfolio = quotes.iloc[0].copy() # ポートフォリオ比率 portfolio[:] = ratio portfolio /= portfolio.sum() # ポートフォリオの正規化 # リバランス計算の実行 start_date = quotes.index[0] for i in range(len(quotes.index)): d = quotes.index[i] # 日付 # (1) 初月は定められた割合で購入。合計10,000円とする if d==start_date: purchase = portfolio * 10000 # 1万円分買う num_of_stocks.loc[d] = purchase / quotes.loc[d] # 購入株数 amount.loc[d] = num_of_stocks.loc[d] * quotes.loc[d] # 評価額 else: # (2) 毎月得た分配金は再投資。保有株数×価格で割合を計算し、目標と乖離がある場合はリバランスする。 # 分配金再投資 reinvested = dividends.loc[d] * num_of_stocks.iloc[i-1] # 該当月の分配金で再投資する金額 num_of_stocks.loc[d] = num_of_stocks.iloc[i-1] + reinvested / quotes.loc[d] # 金額分の株数を追加購入 # 各資産クラスの割合を計算 amount.loc[d] = num_of_stocks.loc[d] * quotes.loc[d] ratio = amount.loc[d] / amount.loc[d].sum() # ポートフォリオとの差 diff_portfolio = portfolio - ratio # 購入 purchase = diff_portfolio * amount.loc[d].sum() num_of_stocks.loc[d] += purchase / quotes.loc[d] amount.loc[d] = num_of_stocks.loc[d] * quotes.loc[d]
amountが資産毎の保有額になりますので、これを使ってリターン・リスクを計算します。
年率平均リターンは、以下の式で求めます。*2
- 年率平均リターン = (最終日の株価÷起算日の株価)1/年数-1
df = amount.sum(axis=1) # すべての資産の合計 days=(df.index[-1] - df.index[0]).days # データの日数 n=int(days/365) # 経過年 annualized_return = ((df.iloc[-1] / df.iloc[0])**(1/n) -1) # トータルリターンを年率換算
df = amount.sum(axis=1) # すべての資産の合計 monthly_return = df.pct_change(freq='1M') # 月次リターン monthly_risk = monthly_return.std() # 月次リターンの標準偏差 annualized_risk = monthly_risk * np.sqrt(12) # 年率化
このポートフォリオの成績計算ロジックを各資産の保有割合ratioを入力として計算するよう関数化します。これにより任意のポートフォリオの成績を評価できるようにします。
3. 多目的最適化
最適化には、Pythonの多目的最適化ライブラリであるpymooを使います。 まずpymooのクラスとして先ほど定義したポートフォリオ計算関数を評価関数とする最適化問題を定義します。
- 各資産の割合を表す変数の範囲は、0から1とする
- 変数の数は資産の種類=12とする
- トータルで100%になるように正規化してから評価する
- すべての変数が0にならないように制約を設ける
- 計算した年率平均のリスクの最小化とリターンの最大化を目的関数とする
- マルチプロセスで並列評価する
from pymoo.core.problem import ElementwiseProblem import multiprocessing from pymoo.core.problem import StarmapParallelization class PortfolioOptimizationProblem(ElementwiseProblem): def __init__(self, quotes, dividends, **kwargs): super().__init__(n_var=12, n_obj=2, n_ieq_constr=1, xl=np.zeros(12), xu=np.ones(12), **kwargs) self.quotes = quotes self.dividends = dividends def _evaluate(self, x, out, *args, **kwargs): score = calc_rebalanced_result(self.quotes, self.dividends, x) f1 = score.iloc[0,0] # リスクの最小化 f2 = -1 * score.iloc[0,1] # 平均リターンの最大化 out["F"] = [f1, f2] out["G"] = -1.0 * np.sum(x) + sys.float_info.epsilon # 変数の合計が0超過の制約 n_proccess = 8 # プロセス数 pool = multiprocessing.Pool(n_proccess) runner = StarmapParallelization(pool.starmap) problem = PortfolioOptimizationProblem(quotes=quotes, dividends=dividends, elementwise_runner=runner)
次にアルゴリズムとパラメータを選択します。多目的最適化アルゴリズムには、遺伝的アルゴリズムの一つであるNSGA-IIを用い、個体数を50、世代数を100として、残りはデフォルトのパラメータとします。
また、各資産割合が100%となる変数を初期解に混ぜてみます。初期解を指定するには、アルゴリズム定義時にsampling引数を指定すれば良いようです*4。
from pymoo.algorithms.moo.nsga2 import NSGA2 from pymoo.termination import get_termination from pymoo.optimize import minimize # NSGA-IIの設定 algorithm = NSGA2( pop_size=50, sampling=np.diag(np.ones(12)), # 初期解 eliminate_duplicates=True ) # 探索の実行 termination = get_termination("n_gen", 100) res = minimize(problem, algorithm, termination, seed=1, save_history=True, verbose=True)
これで最適化を行いました。
4. 結果
上記の条件で最適化を実行したところ、手元のPCで大体3分で計算が終了しました。
最適化で評価したすべての解=ポートフォリオを青点・で、効率的フロンティアにあたるポートフォリオを赤丸●で示したのが以下の図です。数多くあるポートフォリオの中から最もリスクが低く、最大のリターンが出せるポートフォリオが最適化の結果として探索されていることがわかります。

効率的フロンティアの形状を見ると、リスク10%未満の範囲では、リスクに対してリターンがほぼ比例して高くなっています。ところがリスク10%を境にその傾きが低くなっているように見えます。この変化を理解しやすくするため、緑色の補助線を引き、リスクに対するシャープレシオを並べて記載した図を以下に示します。
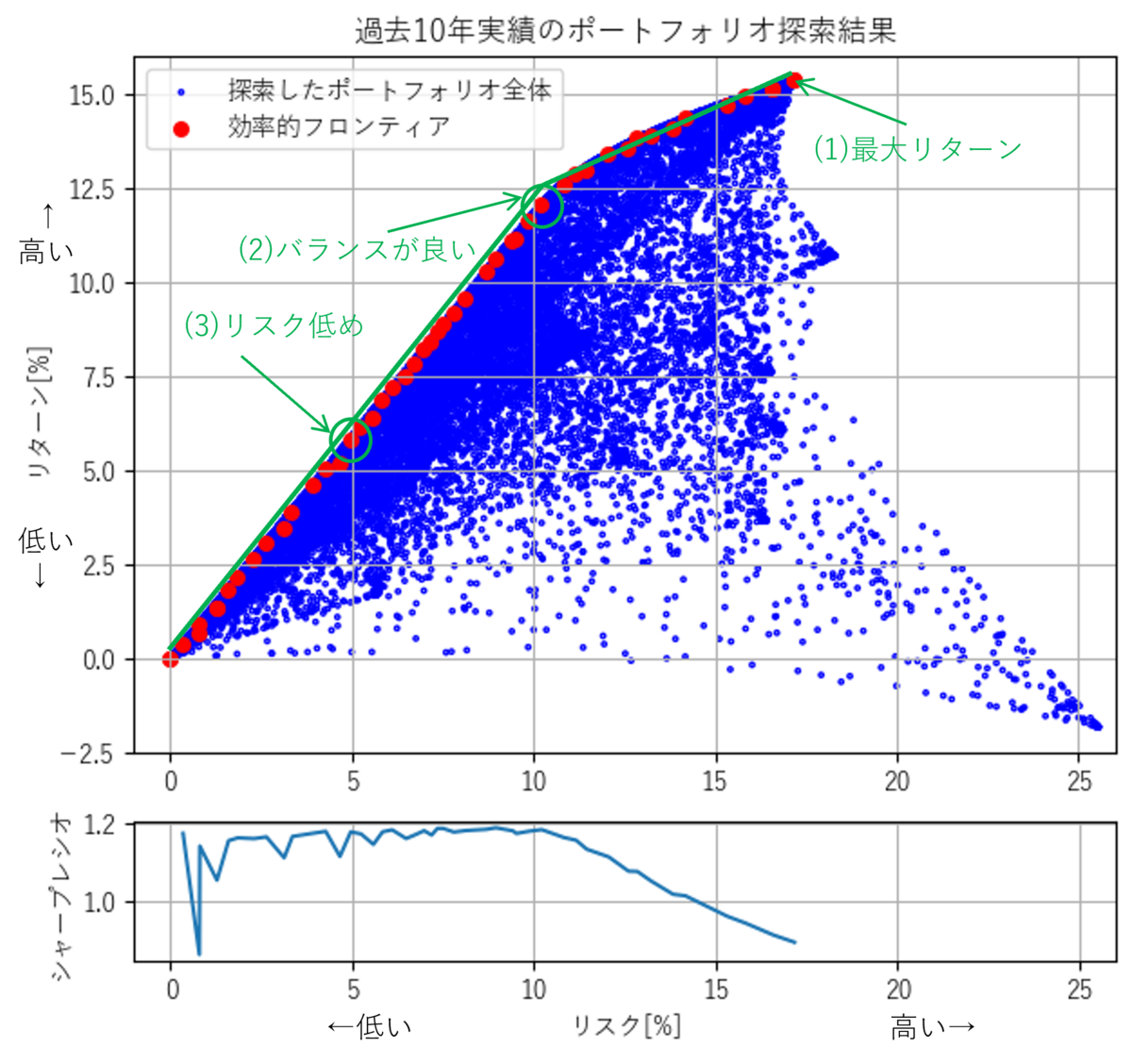
傾きが緩やかであると言う事は、とっているリスクに対して見返りとして期待できるリターンが少ないということになります。実際シャープレシオもリスク10%を超えると低くなっています。そのためリスク10%程度のポートフォリオがシャープレシオが高いポートフォリオの中でも高いリターンの見込めるバランスの良いポートフォリオと言えると思います。
得られた効率的フロンティアのうち、(1)最もリターンの高いポートフォリオ、(2)リスク10%のバランスの良いポートフォリオ、(3)リスクが低め(5%)のポートフォリオの各資産の割合を見てみると、以下のようになりました。
| 資産 | (1)最高リターン | (2)バランス | (3)リスク低め |
|---|---|---|---|
| 現金 | 0.0 | 3.5 | 51.3 |
| 日本株 | 0.0 | 0.0 | 0.0 |
| 米国株 | 100.0 | 46.9 | 19.6 |
| 先進国株 | 0.0 | 0.0 | 0.0 |
| 新興国株 | 0.0 | 0.0 | 0.0 |
| 米国債券 | 0.0 | 0.0 | 0.6 |
| 先進国債券 | 0.0 | 0.0 | 0.1 |
| 日本REIT | 0.0 | 0.0 | 0.0 |
| 米国REIT | 0.0 | 0.0 | 3.0 |
| 先進国REIT | 0.0 | 0.0 | 0.0 |
| コモディティ | 0.0 | 0.0 | 0.0 |
| 金 | 0.0 | 49.1 | 26.0 |
最もリターンの高いポートフォリオは米国株100%ですが、リスク10%のバランスの良いポートフォリオは米国株45%金55%となっており、リスクが低いポートフォリオはそれに現金を混ぜたものになっています。この結果は冒頭の記事の続きの記事で着目されている金50% 米国株50%のポートフォリオと近いものとなっており、最適化の結果としてはそれなりに妥当なものが得られていそうです。
最後に、探索の推移を、解分布の良さを表す指標Hypervolumeを使って見てみます。pymooではminimize()の引数にsave_history=Trueを入れておくと、各世代の変数・評価結果が得られるので、そこからHypervolumeを計算できます。参照点としてリスク最大・リターン最小の点を基準としました。
from pymoo.indicators.hv import HV ref_point = np.array([np.max(F_all[:,0]), np.min(F_all[:,1])]) # 参照点はすべての解のリスク最大リターン最小の点 ind = HV(ref_point=ref_point) hv = [ind(np.array([p.F for p in h.pop])) for h in res.history] plt.plot(hv)
計算したHypervolumeを世代ごとに並べると以下の図のようになりました。今回50個体100世代=5000個のポートフォリオの評価をしていますが、20世代=1000個くらいの評価でおおむね効率的フロンティアの形状は見えていて、そこから少しずつ割合を調整して数値を上げているような推移になっています。もう少し世代数を増やしても改善できそうですが、実用上はこのくらいの評価でも十分いいポートフォリオが得られそうです。

5. まとめ
遺伝的アルゴリズムの1つであるNSGA-IIをつかって、12の資産クラスからなるポートフォリオのうち、低いリスクで高いリターンが得られるポートフォリオの集合(効率的フロンティア)の探索を試してみました。10年間の実績値を使った結果、米国株・金を中心としたポートフォリオが良好な成績を示すことがわかりました。
ただ、こういったポートフォリオをそのまま使えるかというと微妙で、米国株・金に偏っており分散されていないので、米国株・金が同時に下がるようなシチュエーションには(この2つは相関が低いようなので可能性は低そうですが、もしあれば)弱いでしょう。最低限他の資産にも分散させる、といった制約も考えて最適化したほうがよさそうです。
それから、今回考慮しませんでしたが、リバランスには売買手数料・為替手数料や税金がかかってきますし、今後の市場見通しやその不確実性などの情報も考慮しておく必要があると思います。時々刻々と変わってくる株価・市場に対して最適なポートフォリオも変わってくるので、このような最適化方法を使うにしても、最適化自体やポートフォリオを適宜更新するような運用も同時に考える必要がありそうです。
ここまで考えられているのかはわかりませんが、いくつかの証券会社では、ポートフォリオを提案してくれて、自動で運用するものがあるようです*5*6*7。費用が安ければ、こういったサービスを使うのが個人では容易なように思いました。
*1:銘柄については、正直なところ妥当かどうか自信がありません。もしより良い銘柄があれば教えていただきたいです。
*2:リスク・リターン(2)異なる期間の収益率を⽐較する「年率換算」
*5:最適ポートフォリオって何ですか? | ロボアドバイザーならWealthNavi(ウェルスナビ)